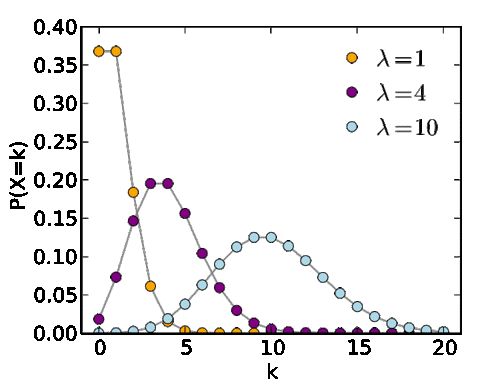
베르누이 분포, 이항 분포
시행의 결과 "값이 성공과 실패 두 가지"만 가지고, 각 시행의 성공 확률이 p, 실패 확률이 1-p인 실험을
베르누이 시행(Bernoulli trial)이라고 부릅니다.
그리고 이 때의 확률 변수 x는 베르누이 분포를 가진다고 하며 수식으로는 다음과 같이 표기한다.
$$$ X\quad \sim \quad Ber(p)\quad \quad Bernoulli\quad Distribution $$$
이항분포란 n번의 서로 독립적으로 반복된 베르누이 시행 중에서
성공한 횟수를 확률 변수 X라고 놓았을 때, 이 변수 X의 확률 분포를 의미한다.
윷놀이의 예시를 들어보겠습니다.
윷놀이에서 각각의 작대기(?)하나를 던지는 것은 앞면 혹은 뒷면의 두 가지 경우의 수를 가지며
앞면이 나올 확률이 1/2인 (아닐 수도 있지만 1/2로 가정하겠습니다.)베르누이 실행이다.
그리고 윷을 한번 던지는 행위는 이러한 베르누이 시행을 4번 반복하는 것을 의미한다.
이제 앞면이 나온 윷의 개수(성공한 시행의 개수)를 확률변수 X로 놓고 확률을 계산해보면 다음과 같습니다.
| X | 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|---|
| P(X=x) | 1/16 | 4/16 | 6/16 | 4/16 | 1/16 |
앞면 하나만 나온 도의 경우를 보겠습니다.
이 경우 네 개의 윳 가운데 하나만 앞면이면 되므로 가능한 윳의 경우는 4가지이다.
그리고 하나의 윳만 앞면으로 나올 수 있는 확률은 1/2 x 1/2 x 1/2 x 1/2로 1/16이다.
그러므로 윷을 한번 던졌을 때 도가 나올 확률은 4 x 1/16 = 4/16이며,
이와 같이 각각의 확률 변수의 확률 값을 계산하는 것을 확률 질량 함수라고 한다.
(probability mass function)
$$$ f(x)=\left(\begin{array}{c}n\\ x\end{array}\right)p^{x}(1-p)^{n-x} $$$
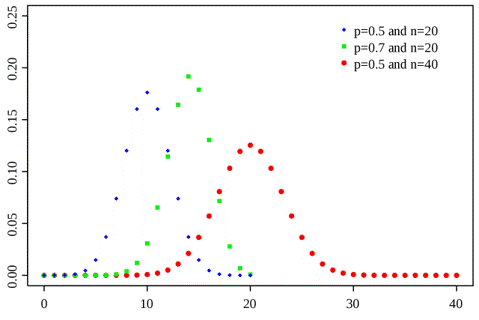
이러한 확률 변수 X를 이항 분포를 띈다고 한다.
이항 분포의 확률 질량함수를 수식으로 표현하면 아래와 같습니다
$$$ X\quad \sim \quad B(n,p)$$$